Архитектура
Компонентами приложения Spark являются:
- Driver(Драйвер)
- Application Master(Мастер приложения)
- Spark Context(Контекст)
- Cluster Resource Manager (Менеджер ресурсов кластера)
- Executors (Исполнители)
Spark использует архитектуру master/slave (ведущий/ведомый) с центральным координатором,
называемым Driver(Драйвер), и набором исполняемых рабочих процессов, называемых Executors,
которые расположены на различных узлах кластера.
Драйвер
Драйвер (Driver) отвечает за преобразование пользовательского приложения в более мелкие единицы выполнения, называемые задачами(Task), а затем планирует их запуск с помощью менеджера кластера(YARN) на исполнителях(Executors).
Драйвер также отвечает за выполнение приложения Spark и возвращает статус/результаты пользователю.
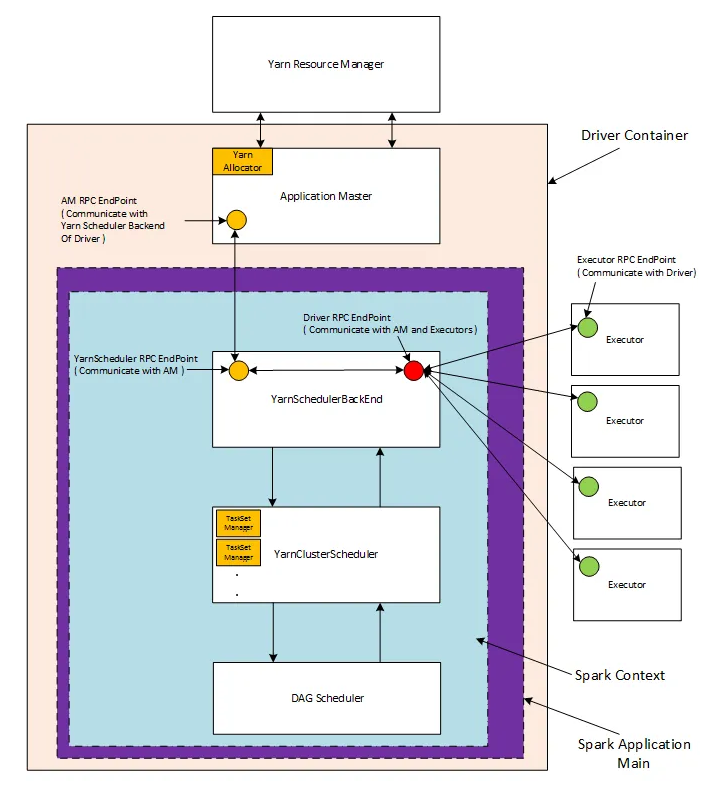
Драйвер Spark содержит различные компоненты - DAGScheduler, TaskScheduler, BackendScheduler и BlockManager. Они отвечают за преобразование пользовательского кода в реальные задания Spark, выполняемые на кластере.
Другие свойства драйвера:
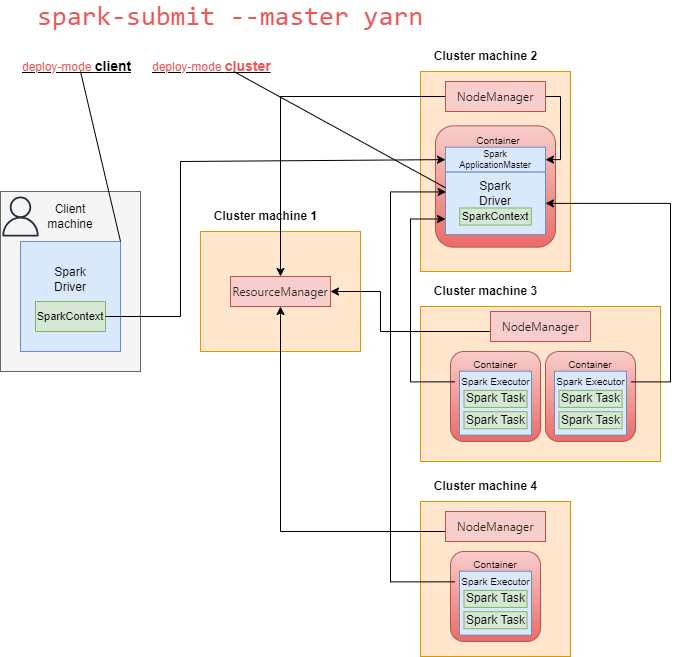
- может выполняться на машине пользователя(deploy-mode client) или на одном из рабочих узлов кластера(deploy-mode cluster) для обеспечения высокой доступности;
- хранит метаданные обо всех RDD(Resilient Distributed Databases) и их партициях(partitions) – это ключевые концепции Spark ;
- создается после того, как пользователь отправляет Spark-приложение менеджеру кластера (в нашем случае YARN);
- запускается в собственной JVM;
- оптимизирует логические преобразования DAG и, если возможно, поэтапно объединяет их, а также определяет наилучшее место для выполнения этой DAG;
- создает Spark WebUI с подробной информацией о приложении;
Мастер приложений
Application Master - это специфическая для каждого распределенного приложения сущность, которой поручено договариваться о ресурсах с ResourceManager и работать с NodeManager для выполнения и мониторинга задач приложения. Каждое приложение, работающее на кластере, имеет свой собственный, выделенный экземпляр Application Master.
Spark Application Master создается одновременно с Driver на том же узле (в случае deploy-mode cluster), когда пользователь отправляет Spark-приложение с помощью spark-submit.
Драйвер сообщает мастеру Spark Application Master о потребностях исполнителей(Executors) для приложения, и мастер приложений договаривается с менеджером ресурсов о выделении ресурсов для размещения этих исполнителей.
В автономном режиме Spark Application Master выступает в роли менеджера кластера.
Spark Контекст
Spark Контекст(Spark Context) - это основная точка входа в функциональность Spark, а значит, и сердце любого приложения Spark. Он позволяет Spark Driver получить доступ к кластеру через менеджер ресурсов кластера и может использоваться для создания RDD, аккумуляторов и широковещательных переменных на кластере.
Spark Context также отслеживает исполнителей в режиме реального времени, регулярно отправляя сообщения heartbeat.
Spark Context создается Spark Driver для каждого Spark-приложения и существует в течение всего времени жизни Spark-приложения.
Spark Context прекращает работу после завершения работы Spark-приложения. Для каждой JVM может быть активен только один Spark Context.
Начиная с Apache Spark 2.0 появилась новая точка входа, называемая SparkSession.
Он объединяет SQLContext, HiveContext и StreamingContext. Все API, доступные в этих контекстах, также доступны в SparkSession.
Менеджер ресурсов кластера
Менеджер кластера в распределенном приложении Spark - это процесс, который контролирует, управляет и резервирует вычислительные ресурсы в виде контейнеров на кластере. Эти контейнеры резервируются по запросу мастера приложения и выделяются им, когда они освобождаются или становятся доступными.
После выделения контейнеров менеджером кластера мастер приложений передает ресурсы контейнеров обратно драйверу Spark, а драйвер Spark отвечает за выполнение различных шагов и задач приложения Spark.
SparkContext может подключаться к различным типам менеджеров кластеров. Сейчас наиболее популярны YARN и Kubernetes.
Исполнители
Исполнители - это процессы на рабочих узлах, задачей которых является выполнение поставленных задач. Эти задачи выполняются на рабочих узлах и затем возвращают результат драйверу Spark.
Исполнители запускаются один раз в начале работы Spark Application и затем работают в течение всего времени существования приложения; Такая инициализация называется Static Allocation of Executors (статическое выделение исполнителей). Однако пользователи также могут выбрать динамическое выделение исполнителей(dynamically allocate executors), при котором они могут добавлять или удалять исполнителей в Spark динамически, чтобы соответствовать общей рабочей нагрузке (но это может повлиять на другие приложения, работающие на кластере). Даже если несколько исполнителей Spark выйдут из строя, приложение Spark сможет продолжить работу.
Другие свойства исполнителя:
- хранит данные в кэше в куче JVM или на диске
- считывает данные из внешних источников
- записывает данные во внешние источники
- выполняет всю обработку данных
Ниже представлена большая картинка, демонстрирующая основные компоненты контейнера с драйвером Spark, работающего в кластере YARN.