Датафрейм(DataFrame) - это неизменяемый набор записей, организованных в именованные столбцы.
Каждый столбец в DataFrame имеет имя и связанный с ним тип. Датафрейм похож на таблицу в реляционной базе данных и реализован на поверх RDD(более просто — это набор трансформаций для создания таблицы).
Датафреймы при использовании pyspark гораздо эфективнее низкоуровневых RDD в плане производительности из за наличия под капотом датафреймов оптимизатора запросов Catalyst, поэтому в большинстве случаев в pyspark'е все работают с датафреймами.
Ключевые аспекты Spark DataFrame:
1. Создание DataFrames
Вы можете создавать DataFrames из различных источников, таких как структурированные файлы данных (CSV, Parquet, JSON и т. д.), существующие RDD, таблицы Hive или даже путем явного указания схемы датафрейма.
В качестве примера создадим DataFrame на основе содержимого JSON-файла:
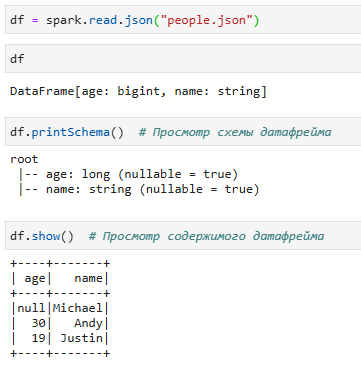
По сути, DataFrame - это RDD со схемой. Схема может быть либо выведена из данных как в примере выше, либо определена как StructType. StructType - это встроенный тип данных в Spark, который мы используем для представления коллекции объектов StructField.
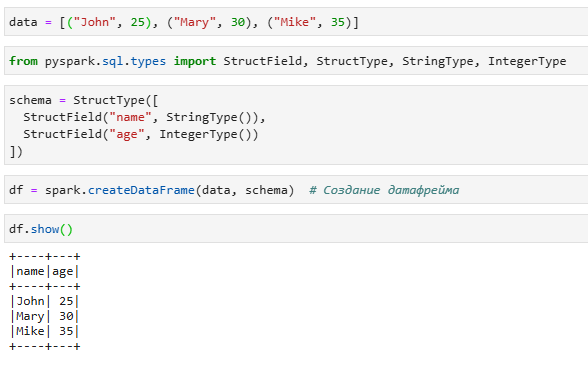
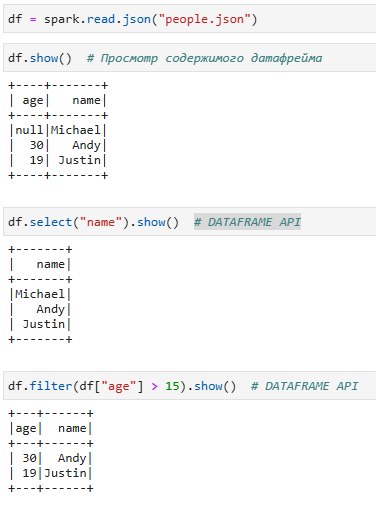
2. Использование DSL
DSL это domain-specific language, DSL — «язык, специфический для предметной области» , называемый так же DataFrame API. Цель DataFrame API - предоставить высокоуровневую абстракцию, которая одновременно выразительна и проста в использовании.
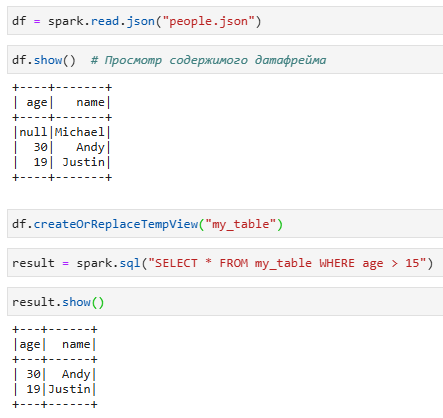
3. SQL-запросы
Вы можете зарегистрировать DataFrame в качестве временной таблицы, а затем выполнять на нем SQL-запросы.
4. Совместимость
Spark DataFrame можно использовать с другими библиотеками Spark, такими как Spark MLlib для машинного обучения и Spark Streaming для обработки данных в реальном времени.
5. Оптимизация производительности
Spark выполняет оптимизацию под капотом, чтобы повысить производительность операций с DataFrame.
Оптимизатор Catalyst в Spark оптимизирует логический план операций с DataFrame перед их выполнением. Затем механизм выполнения Tungsten преобразует оптимизированный план в физический план выполнения, делая операции более эффективными.
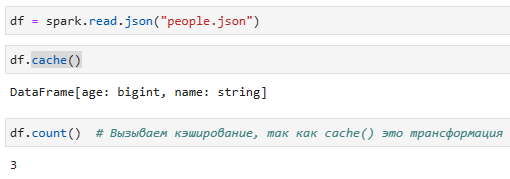
6. Кэширование
Вы можете сохранять DataFrames в памяти для итеративных алгоритмов или для повторного использования, чтобы избежать повторных вычислений.
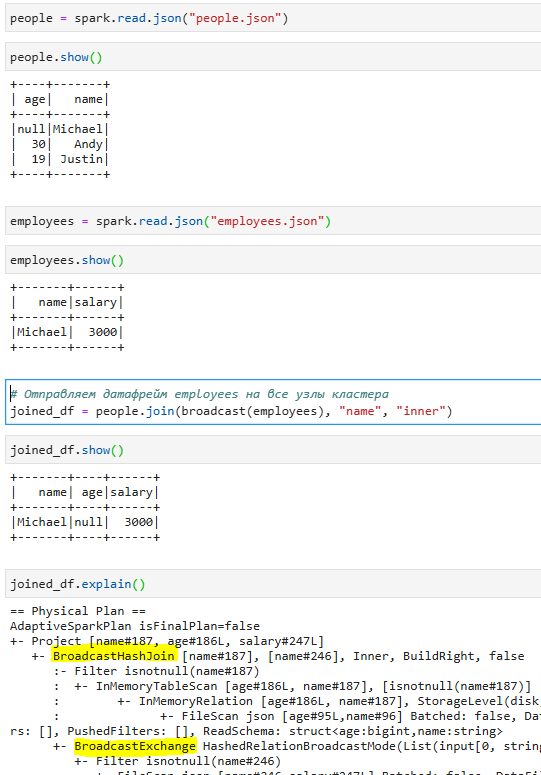
7. Broadcasting(трансляция)
Трансляция - это техника, при которой небольшой датафрейм отправляется на все рабочие узлы в кластере Spark, что позволяет им эффективно выполнять операции присоединения без необходимости перемешивать большие объемы данных по сети.
DataSet API
Использовать DataSet API в pySpark не получится, так как Spark реализует DataSet API только для Scala и Java, но знать о его существовании необходимо. Основная причина, по которой Dataset API недоступен на языке Python заключается в отсутствии статической типизации в нем.
Dataset представляет собой набор строго типизированных объектов JVM, определяемых классом в Scala или Java. Концептуально Spark DataFrame - это псевдоним для коллекции универсальных объектов Dataset [Row], где Row - это универсальный нетипизированный объект JVM. Dataset, напротив, представляет собой коллекцию сильно типизированных объектов JVM, заданный вами классом на Scala или Java.