Аналогия с операционной системой
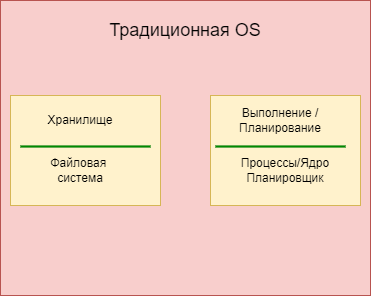
Чтобы понять, что такое Hadoop, я проведу аналогию с операционной системой. Традиционная операционная система на высоком уровне состоит из нескольких частей: файловой системы и вычислительного компонента.
На одной машине есть файловая система, она может быть разной: FAT32, HPFS, ext2, NFS, ZFS и т.д. Вычислительный компонент содержит в себе ядро, планировщик, а также процессы, которые позволяют программам работать с данными.
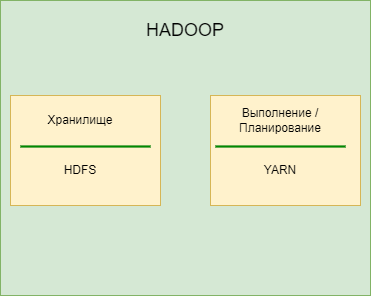
Когда мы переносим эту концепцию хранения/обработки данных на уровень кластера Hadoop, мы получаем практически то же разделение, те же два компонента. Но в качестве слоя хранения вместо традиционной файловой системы будет использоваться HDFS - распределенная файловая система Hadoop. А YARN (Yet Another Resource Negotiator) берет на себя роль вычислительного компонента: выполнение, планирование.
Архитектура HDFS
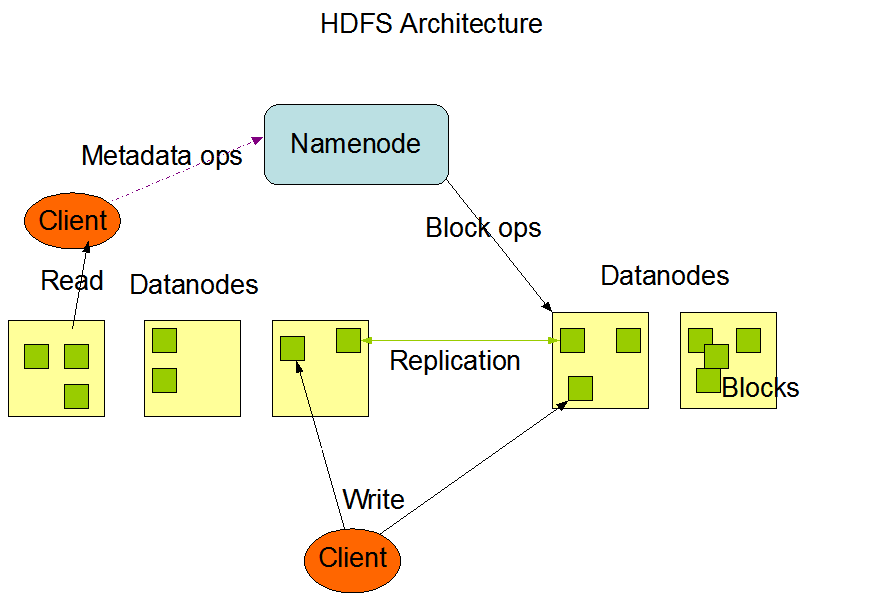
HDFS хранит файлы поблочно. Блоки в HDFS распределены между узлами данных вычислительного кластера. Все блоки (кроме последнего блока файла) имеют одинаковый размер, кроме того блок может быть размещён на нескольких узлах.
HDFS состоит из двух обязательных компонентов:
-
Узел имен (NameNode) - программный код, отвечающий за файловые операции, такие как открытие и закрытие файлов, создание и удаление каталогов.
Кроме того, NameNode отвечает за:- управление пространством имен файловой системы;
- управление доступом со стороны внешних клиентов;
- соответствие между файлами и реплицированными на узлах данных блоками.
-
Узел данных (DataNode) – программный код, отвечающий за операции уровня файла, такие как: запись и чтение данных, выполнение команд создания, удаления и репликации блоков, полученные от узла NameNode.
Кроме того, узел DataNode отвечает за:- периодическую отправку сообщения о состоянии (heartbeat-сообщения);
- обработку запросов на чтение и запись, поступающие от клиентов файловой системы HDFS, т.к. данные проходят с остальных машин кластера к клиенту мимо узла NameNode.
HDFS реплицирует блоки файлов для обеспечения отказоустойчивости на уровне блоков. Каждый блок имеет несколько копий в HDFS.
Процесс создания (записи) файла HDFS:
1. Клиент разделяет исходные данные на части размером, равным размеру блока.
2. Клиент подключается к NameNode и требует начать процедуру записи файла, указав фактор репликации для этого файла.
3. NameNode возвращает список DataNodes, где следует разместить все реплики первого блока данных.
4. Клиент посылает запрос на запись первого блока в первую ноду по списку. Если не удается установить соединение, клиент выбирает следующую ноду из списка и так далее.
5. Первая нода записывает блок и передает его копию в следующую ноду по списку. Эта нода записывает блок и передает его копию следующей ноде и так далее.
6. После завершения записи блока DataNodes посылают сообщение об успешном завершении операции по цепочке в обратном направлении к клиенту.
7. После получения первого подтверждения об успешной записи клиент уведомляет NameNode о записи блока и получает список нод для записи второго блока и так далее
Процесс чтения файла HDFS:
1. Клиент обращается к NameNode с запросом о местоположении DataNode, содержащих блоки данных.
2. NameNode сначала проверяет наличие требуемых привилегий, и если у клиента достаточно привилегий, NameNode отправляет местоположение DataNode, содержащих блоки
3. Клиент напрямую взаимодействует с DataNode. Клиент отправит запрос ближайшим(происходит выбор наилучшего сетевого маршрута т.к датаноды могут находиться в разных датацентрах на разных континентах) DataNode
4. Клиент начинает считывать данные из DataNode. Данные будут напрямую передаваться из DataNode клиенту.
Архитектура YARN
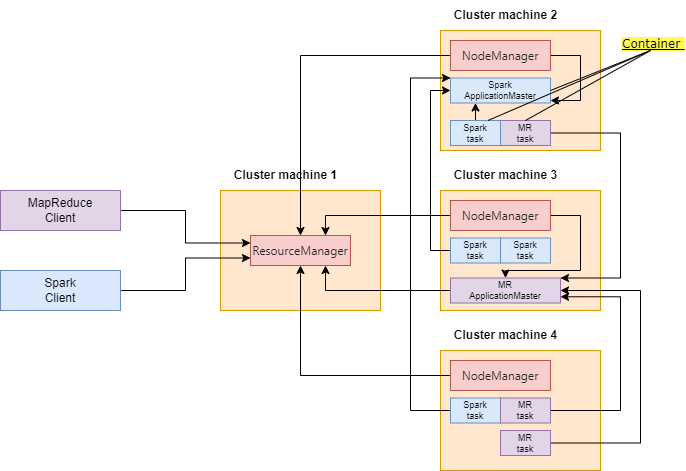
YARN имеет базовый сервис — ResourceManager . ResourceManager — это “директор”, который принимает решения о распределении ресурсов между всеми приложениями в системе. У него есть служащие, которые работают на всех узлах кластера, называемые NodeManager, обеспечивающие выделение ресурсов по запросу ResourceManager.
Ресурсы представлены контейнерами - коллекциями физических ресурсов, таких как оперативная память, ядра процессора и дисковое пространство.
При запуске нового приложения в кластере, ResourceManager выделяет ресурсы для ApplicationMaster . ApplicationMaster — это специфичная для каждого приложения сущность, которой поручено согласование ресурсов с ResourceManager и взаимодействие с NodeManager для запуска приложений в контейнерах и мониторинга процесса их выполнения.
После запуска ApplicationMaster будет отвечать за весь жизненный цикл распределенного приложения. Прежде всего, он будет отправлять запросы ресурсов в ResourceManager, чтобы получить контейнеры, необходимые для выполнения задач приложения. Запрос ресурсов — это просто запрос на контейнеры, которые соответствуют некоторым требованиям к ресурсам, например:
- Количество ресурсов, выраженное в мегабайтах памяти и процессорных ядрах.
- Предпочтительное расположение контейнера(имя хоста)
- Приоритет в рамках очереди
ApplicationMaster запускается в контейнере, как и любое другое приложение. ResourceManager хранит информацию о запущенных приложениях и выполненных задачах в HDFS. При перезапуске ResourceManager воссоздает состояние приложений и перезапускает только те задачи, которые не были завершены.
Запуск приложения
Давайте рассмотрим последовательность шагов запуска приложения:
1. Клиентское приложение отправляет приложение, включая необходимые спецификации для запуска ApplicationMaster , специфичного для данного приложения.
2. ResourceManager запускает ApplicationMaster.
3. ApplicationMaster регистрируется в ResourceManager . Регистрация позволяет клиентскому приложению запрашивать определенную информацию из ResourceManager , которая позволяет ей напрямую взаимодействовать с ApplicationMaster.
4. ApplicationMaster запрашивает у ResourceManager подходящие контейнеры для запуска приложения.
5. После успешного получения контейнеров ApplicationMaster запускает их, предоставляя NodeManager(ам) их конфигурации.
6. Внутри контейнеров он запускает код пользовательского приложения. Затем NodeManager(ы) предоставляют ему информацию (фазу выполнения, статус) для ApplicationMaster.
7. Во время выполнения пользовательского приложения клиент взаимодействует с ApplicationMaster для получения статуса приложения.
8. После завершения работы приложения и выполнения всех необходимых работ ApplicationMaster отменяет регистрацию в ResourceManager и завершает работу, освобождая контейнеры для других целей.