PySpark позволяет запускать Python-код на Apache Spark - фреймворке на базе JVM.
Как это возможно?
Модель выполнения PySpark
Разделение между Python и JVM на высоком уровне заключается в следующем:
- Обработкой данных занимаются процессы Python.
- Сохранение и передача данных осуществляется процессами Spark JVM.
Программа-драйвер Python взаимодействует с локальной JVM, на которой запущен Spark, через Py4J.
Схема:
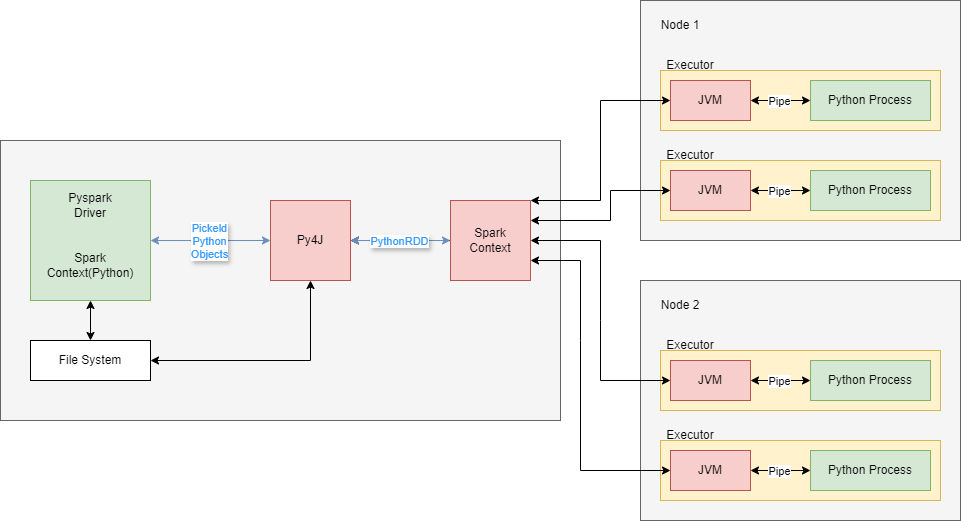
SparkContext и Py4J
Программа драйвера PySpark начинается с инициализации SparkContext; либо напрямую либо косвенно с помощью SparkSession:

Что на самом деле делает pyspark.SparkContext?
Давайте посмотрим на его официальную документацию:
Основная точка входа в функциональность Spark. SparkContext представляет собой соединение с кластером Spark и может использоваться для создания RDD и широковещательных переменных на этом кластере.
Это немного вводит в заблуждение. Единственное, что действительно делает SparkContext в Python, - это подключается к сетевому порту на вашем компьютере и через этот порт связывается с объектом SparkContext в программе JVM (Spark). Затем ваш Python SparkContext сообщает Java SparkContext, что вы хотите сделать.
Представьте, что вы летите на своем частном самолете и говорите своему помощнику Джону Смиту, что хотите отправиться в Найроби, Кения. Джон Смит идет в кабину и говорит с пилотом (тоже Джоном Смитом). Затем пилот направляет самолет в Найроби. Они называются одинаково, но реальный полет выполняет только Джон Смит-пилот.
Аналогично, SparkContext в Java - это тот, кто на самом деле делает все крутые, тяжелые вещи Spark, такие как запуск заданий и получение результатов. Объект Python - это, по сути, телефон, через который вы говорите с объектом Java.
Аналогично, вся библиотека PySpark - это тонкий слой Python на тяжелом механизме Java.
Как PySpark общается с процессом Java?
PySpark может делать что-то внутри процесса JVM благодаря библиотеке Python под названием Py4J.
Py4J позволяет программам на Python:
- открывать порт для прослушивания (по дефолту 25334)
- запустить программу в JVM
- заставить JVM-программу слушать другой сетевой порт (по дефолту 25333)
- посылать команды процессу Java и прослушивать ответы
Главным минусом Py4J является скорость передачи данных между Python и Java, так как взаимодействие происходит через сокеты. Представьте, что вы загружаете в Python pandas датафрейм размером 5 ГБ, что-то с ним делаете, а затем отправляете в Spark. Этот датафрейм нужно будет сериализовать (в питоне это называется pickling) в поток байтов, передать через сокет в JVM, который затем десериализует его... А затем Spark должен будет снова сериализовать результаты, чтобы вернуть их в Python.