Материализация RDD иногда может быть дорогостоящей в плане затрат ресурсов, чтобы предотвратить это, Apache Spark может кэшировать RDD в памяти (или на диске) и повторно использовать их без лишних затрат ресурсов. В Spark RDD, который не кэширован и не отмечен контрольной точкой, будет вычислятся каждый раз при вызове действия.
В Apache Spark есть два API-вызова для кэширования - cache() и persist(). Разница между ними заключается в том, что cache() сохраняет данные в оперативной памяти каждого отдельного узла, если для этого есть место, в противном случае они будут храниться на диске, а persist(level) может сохранять данные в памяти, на диске или вне памяти кучи в сериализованном или несериализованном формате в соответствии со стратегией кэширования, указанной уровнем хранения. cache() - это псевдоним для persist(StorageLevel.MEMORY_AND_DISK).
В спарке RDD вычисляются лениво, то есть RDD не создается до тех пор, пока не будет вызвано действие, а ни cache(), ни persist() не являются действиями.
Стратегии кэширования
В Apache Spark существует несколько уровней хранения данных:
- MEMORY_ONLY. Данные кэшируются в памяти только в несериализованном формате.
- MEMORY_AND_DISK. Данные кэшируются в памяти. Если памяти недостаточно, выгруженные из памяти блоки сериализуются на диск. Этот режим рекомендуется, когда повторное вычисление RDD стоит дорого, а ресурсы памяти ограничены.
- DISK_ONLY. Данные кэшируются на диск только в сериализованном формате.
- OFF_HEAP. Блоки кэшируются вне кучи.
После определения уровня хранения RDD он не может быть изменен.
Сериализация
Описанные выше стратегии кэширования могут также использовать сериализацию для хранения данных в сериализованном формате. Сериализация увеличивает накладные расходы на обработку, но уменьшает объем памяти, занимаемой большими наборами данных. Это может сэкономить место в 2-4 раза, но повлечет за собой дополнительные расходы за сериализацию/десериализацию. Кроме того, при хранении данных в виде сериализованных массивов байтов, создается меньше Java-объектов и, следовательно, снижается нагрузка на GC.
Использование сериализации включается путем добавления суффикса «_SER» к вышеупомянутым схемам - MEMORY_ONLY_SER, MEMORY_AND_DISK_SER.
Стоит отметить, что DISK_ONLY и OFF_HEAP всегда сохраняют данные в сериализованном формате.
Репликация
Данные также могут быть реплицированы на другой узел путем добавления суффикса «_2» к уровню хранения - MEMORY_ONLY_2, MEMORY_AND_DISK_SER_2. Репликация полезна для ускорения восстановления в случае отказа одного узла.
Пример:
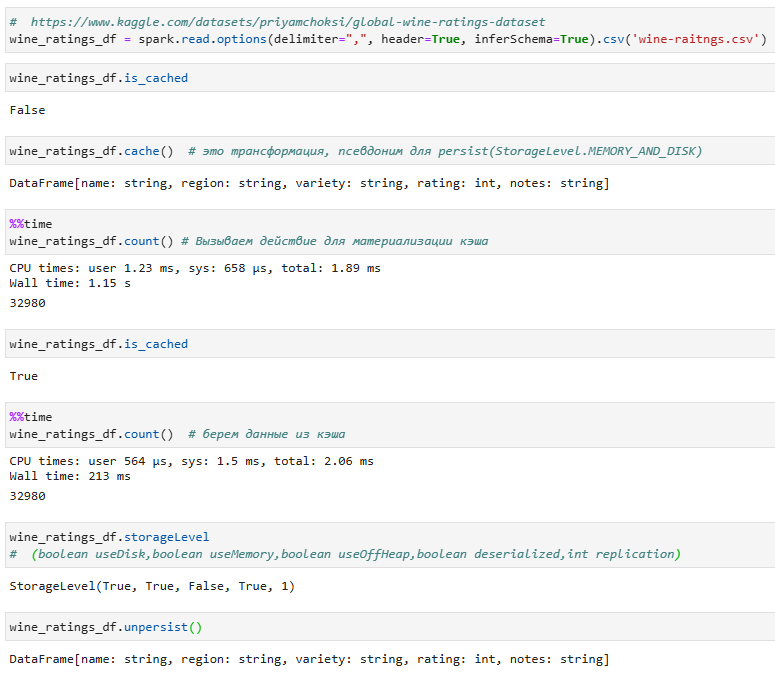
С этим датафреймом выполняется несколько действий. При первом вызове действия данные кэшируются. Дальнейшие действия используют кэшированные данные. В данном примере кэширование ускоряет выполнение, позволяя избежать повторного вычисления датафрейма(RDD).
CacheManager
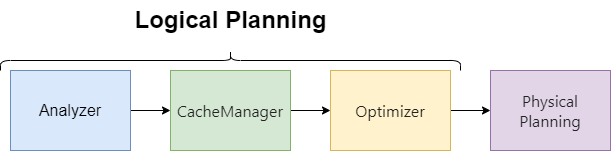
persist использует CacheManager для кэширования запросов в памяти. Фаза CacheManager является частью логического планирования и выполняется после анализатора и перед оптимизатором.
Что это значит?
Посмотрите на пример ниже и обратите внимание на Analyzed Logical Plan:
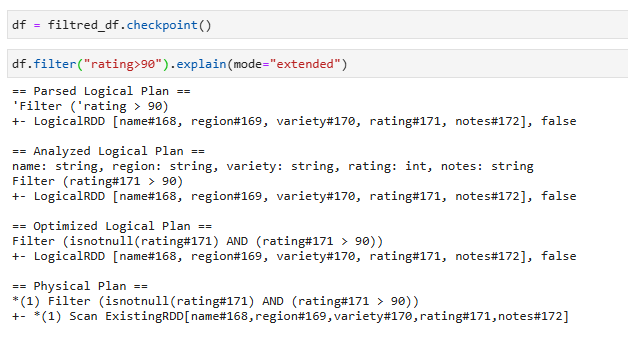
Логично было бы предположить, что такой датафрейм wine_ratings_df.filter("rating>90").select("name", "rating") тоже будет использовать кэшированые данные(появится узел InMemoryRelation)
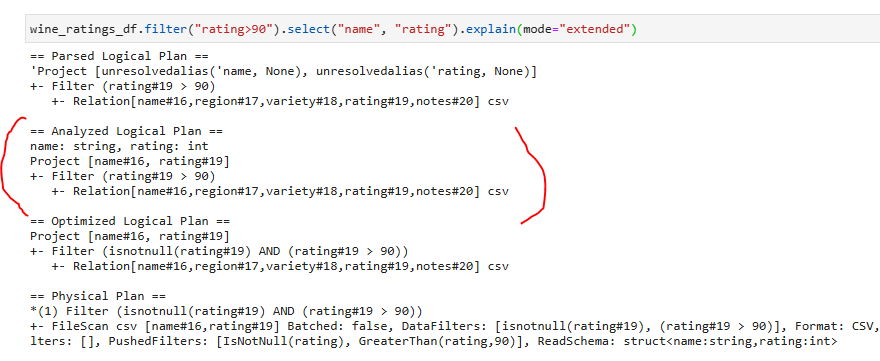
Но как мы видим это не происходит. Все потому что фаза CacheManager происходит ДО оптимизатора. Поэтому запрос не будет использовать кэш потому, что проанализированные планы отличаются.
Checkpoint
Checkpoint(Контрольная точка) - это материализованная версия RDD (датафрейма), которая хранится в распределенной файловой системе, такой как Hadoop Distributed File System (HDFS) или Amazon S3.
Контрольные точки служат двум основным целям:
- Оптимизация производительности: При создании контрольной точки Spark сохраняет DataFrame в надежной и распределенной системе хранения. Это уменьшает необходимость повторно вычислять трансформации DataFrame из исходного источника данных в случае сбоев или повторных вычислений. Это может значительно повысить производительность итеративных алгоритмов или длинных конвейеров обработки данных.
- Надежность и отказоустойчивость: Контрольные точки позволяют быстро восстанавливаться после сбоев. В случае сбоя узла или проблем во время обработки данных Spark может использовать данные, сохраненные в контрольных точках, для перезапуска вычислений, что снижает риск потери данных или искажения результатов.
Контрольные точки можно использовать для усекания логического плана, что особенно полезно в итерационных алгоритмах, в которых план может расти в геометрической прогрессии.
Однако в отличие от cache и persist, вам придется вручную удалять контрольную точку, если она вам больше не нужна.
Пример:
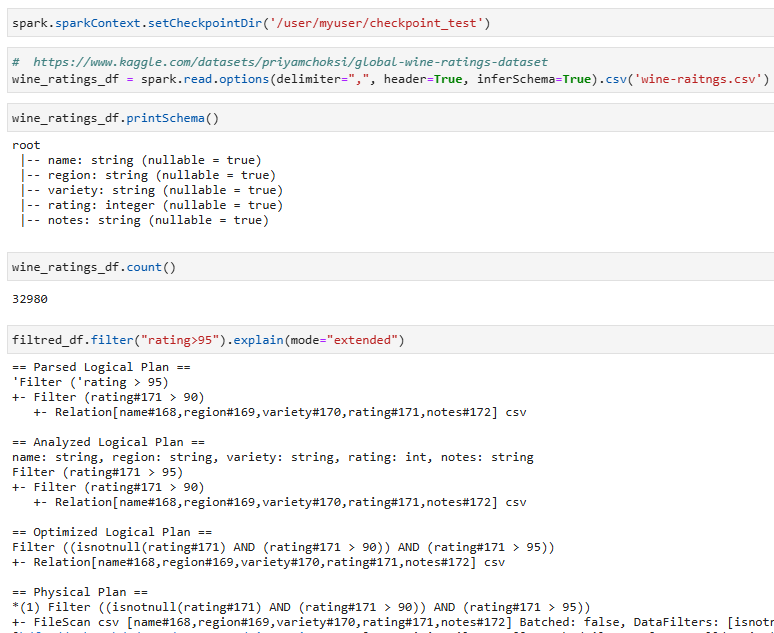
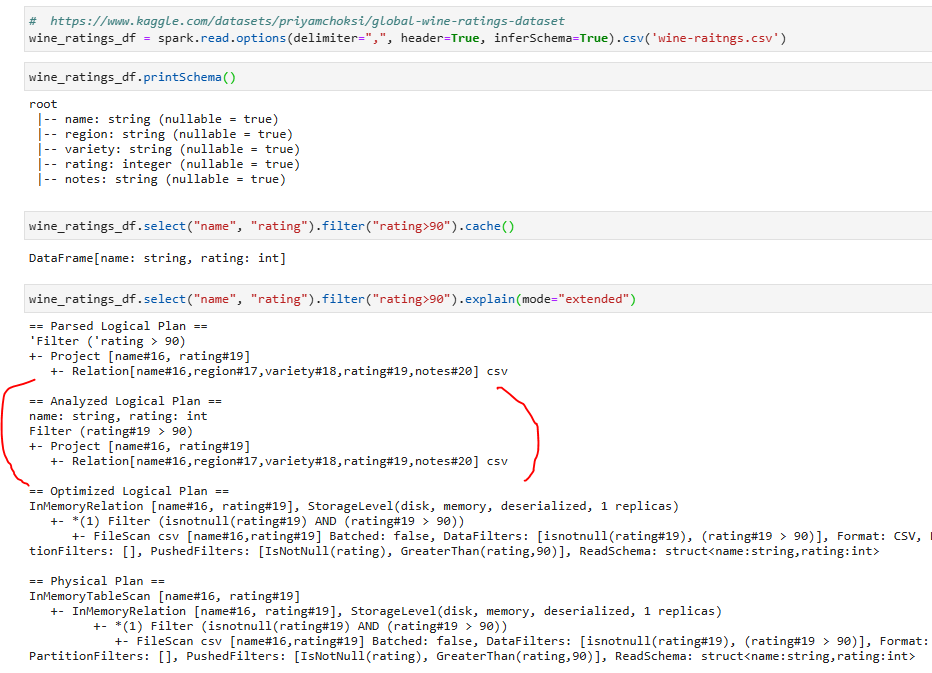
Используем контрольную точку