RDD - базовая концепция Spark
Ключом к пониманию Apache Spark является RDD - Resilient Distributed Dataset(устойчивый распределенный набор данных).
RDD содержит произвольную коллекцию объектов.
Каждый набор данных в RDD распределяется между узлами кластера, чтобы их можно было обрабатывать параллельно.
RDD неизменяемы — их нельзя изменить после создания и распространения по кластеру.
Физически RDD хранится как объект JVM на драйвере и ссылается на данные, хранящиеся либо в постоянном хранилище
(HDFS, S3, PostgreSQL и т. д.), либо в кэше (память, память+диск, только диск и т. д.), либо на другом RDD.
Если сказать прямо, то Apache Spark — это просто реализация RDD.
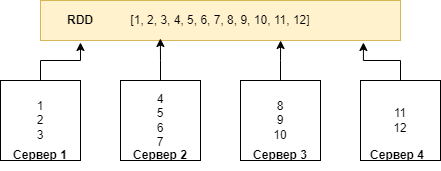
Пример RDD:
RDD хранит следующие метаданные:
- Partitions - набор партиций данных, связанных с этим RDD. Они расположены на узлах кластера. Одна партиция- минимальная партия данных, которая может быть обработана каждым узлом кластера;
- Dependencies - список родительских RDD, участвующих в вычислении, так называемый линейный граф;
- Computation - функция для вычисления дочерних RDD из родительских RDD;
- Preferred Locations - где лучше всего разместить вычисления по разделам (локальность данных);
- Partitioner - как данные делятся на разделы (по умолчанию они делятся с помощью HashPartitioner);
При сбое RDD может быть воссоздан, поскольку каждый RDD знает, как он был создан
(благодаря хранению линейного графа).
Кроме того, RDD могут быть материализованы, в памяти или на диске.
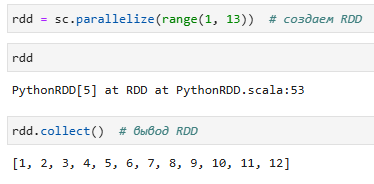
Пример RDD pyspark:
RDD также можно кэшировать и разбивать вручную. Кэширование полезно, когда мы используем определенный
RDD несколько. А ручное разбиение важно для правильной балансировки данных между партициями.
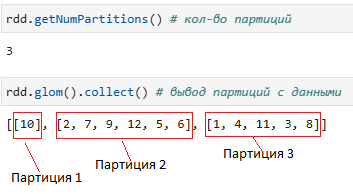
Проверим количество партиций и данных в них:
Почему RDD неизменяемы?
На это есть несколько причин:
- Влияние функционального программирования - Apache Spark разработан с сильным влиянием парадигмы функционального программирования. Функциональное программирование подчеркивает неизменяемость и чистые функции.
- Поддержка одновременного потребления - RDD предназначены для поддержки параллельной обработки данных. В распределенной среде, где несколько узлов могут получать доступ к данным и обрабатывать их одновременно, неизменяемость становится критически важной. Неизменяемые структуры данных гарантируют, что данные остаются согласованными между потоками, устраняя необходимость в сложных механизмах синхронизации и снижая риск возникновения условий гонки. Каждое преобразование создает новый RDD, устраняя риск возникновения условий гонки и обеспечивая целостность данных.
- Вычисления в оперативной памяти - Apache Spark известен своей способностью выполнять вычисления в памяти, что значительно повышает производительность. Хранение данных в памяти обеспечивает высокоскоростной доступ к ним, и неизменяемость играет здесь ключевую роль. Неизменяемые структуры данных устраняют необходимость частой инвалидации кэша(процесс удаления данных кэша, которые больше не являются действительными или актуальными), что упрощает поддержание согласованности и надежности в высокопроизводительной вычислительной среде.
- Линейность и отказоустойчивость - Resilient(Устойчивый) в RDD означает способность быстро восстанавливаться после сбоев. Такая устойчивость очень важна для распределенных вычислений, где сбои могут происходить относительно часто. RDD обеспечивают отказоустойчивость с помощью линейного графа (или информации о линейном графе). Линейный граф - это возможность восстановить потерянный или поврежденный RDD, проследив историю его преобразований. Поскольку RDD неизменяемы, они обеспечивают детерминированный способ восстановления предыдущего шага даже после сбоя. Эта функция отслеживания истории очень важна для обеспечения отказоустойчивости и восстановления данных в Spark. Если бы RDD были изменяемыми, было бы сложно восстанавливать предыдущее состояние в случае сбоев узлов. Неизменяемость обеспечивает сохранность информации о состоянии и позволяет Spark надежно восстанавливать потерянные данные.
Трансформации и действия
Все самое интересное, что происходит в Spark, происходит через операции с RDD. То есть обычно приложения Spark выглядят следующим образом - мы создаем RDD (например, читаем данные в виде файла из HDFS), трансформируем их (map, reduce, join, groupBy, aggregate, reduce, ...), делаем что-то с результатом (например, сбрасываем его обратно в HDFS).
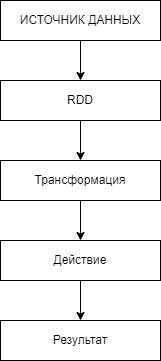
С помощью RDD можно выполнять два типа операций над RDD (и, соответственно, вся работа с данными происходит в последовательном выполнении цепочки из этих двух типов): трансформации(transformations) и действия(actions).
Трансформации
Результатом применения этого типа операции к RDD является новый RDD. Как правило, это операции, которые каким-то образом преобразуют элементы данных. Трансформации по своей природе ленивы(lazy) (еще их называют отложенными), то есть когда мы вызываем какую-то операцию над RDD, она не выполняется немедленно. Spark хранит запись о том, какая операция была вызвана (используя DAG). Благодаря трансформациям мы можем начать выполнение операций в любой момент, вызвав действие над RDD. Следовательно, данные не загружаются до тех пор, пока они не понадобятся, пока не вызовется действие. Это дает широкие возможности для низкоуровневых оптимизаций. Существуют две группы трансформаций, а именно:
- узкие трансформации(narrow transformations)
- широкие трансформации (wide transformations).
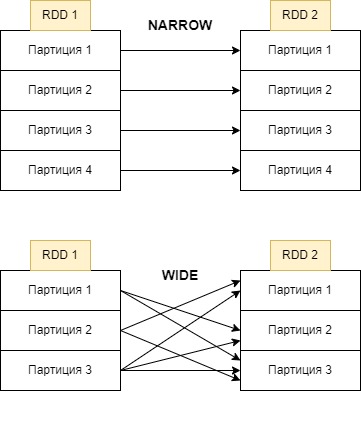
Узкая трансформации не требует перемешивания(shuffle) или реорганизации данных между партициями. Пример таких трансформаций это map, filter и т. д.
Перемешивание происходит при перегруппировке данных между партициями. Это необходимо, когда для преобразования требуется информация из других партиций, например суммирование всех значений в столбце. Spark соберет необходимые данные из каждой партиции и объединит их в новую партицию. Перемешивание почти всегда вызывает сетевой обмен данными между экзекьюторами и соответственно узлами кластера, что является очень ресурсоемкой операцией.
Посмотрим на узкую трансформацию filter:
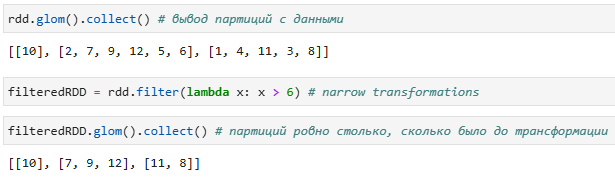
В этом примере , каждая партиция может быть обработана независимо от другой партиции.
При широкой трансформации (groupByKey, join и т. д.) данные, необходимые для обработки, могут находиться в нескольких партициях родительского RDD, которые необходимо объединить. Для реализации этих операций Spark должен выполнить перетасовку, перемещая данные по кластеру и формируя новый RDD с новым набором партиций(широкие трансформации могут изменить количество партиций), как показано в примере ниже:
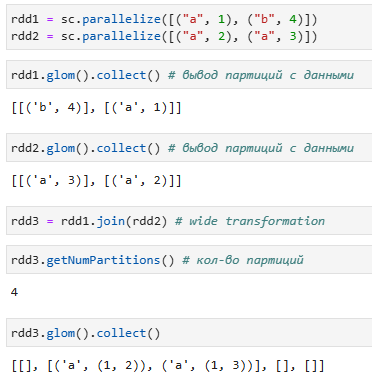
Узкие трансформации не только более эффективны с точки зрения производительности, так как не предполагают сетевой передачи данных (а также подготовки к ней, включающей работу с диском и сериализацию), но и более надежны в ситуациях утраты части данных.
Действия
Действия применяются, когда необходимо материализовать результат - сохранить данные на диск, записать их в базу данных или вывести часть данных на консоль. Операция collect, которую мы использовали, также является действием.
Действия не являются ленивыми(lazy) - они сразу запускают обработку данных(создают job ‘ы). Действия - это операции RDD, которые производят значения, не являющиеся RDD.
Например, чтобы получить кол-во элементов в RDD, мы можем использовать действие count:
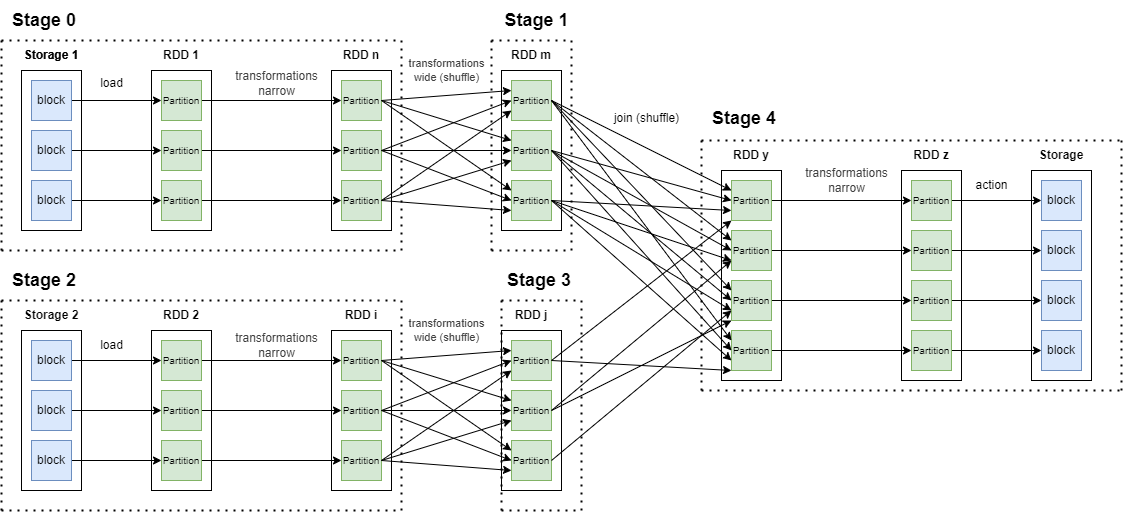
DAG
DAG (Directed Acyclic Graph Направленный Ациклический Граф) в Spark— это фундаментальная концепция, которая играет важную роль в модели выполнения Spark. DAG является «направленным», поскольку операции выполняются в определенном порядке, и «ацикличным», поскольку в плане выполнения нет циклов или петель. Это означает, что каждый этап зависит от завершения предыдущего этапа, и каждая задача на этапе может выполняться независимо от другой.
Непосредственно запуском вычислений над данными в Spark управляет DAGScheduler, находящийся в драйвере приложения. DAGScheduler отвечает за:
- создание выполняемого графа приложения;
- генерацию задач, назначение и их рассылку на экзекьютеры;
- мониторинг хода их выполнения;
- отслеживание событий отказа и принятие решения о перезапуске или остановке вычислений;
Материализованная форма графа состоит из стадий (stage). Стадия представляет собой последовательность RDD, связанных узкими трансформациями. Результатом такой стадии является либо сетевой обмен данными между executor’ами и соответственно узлами кластера(shuffle), либо сохранение результатов во внешнее хранилище, либо, в определенных случаях, возвращение данных в драйвер приложения (collect). Объединение функций обработки по узким трансформациям позволяет не генерировать промежуточных наборов данных и таким образом избежать ненужных накладных расходов на запись на диск данных, их сериализацию / десериализацию.