Партиции
Apache Spark - это движок для параллельной обработки данных на кластере. Параллелизм в Spark позволяет разработчикам параллельно и независимо выполнять задачи на сотнях машин в кластере. Все благодаря базовой концепции Spark - RDD.
Под капотом эти RDD хранятся в партициях(partitions) на разных узлах кластера. По сути, партиция - это логический кусок большого набора данных. Он дает возможность распределить работу по кластеру, разбить задачу на более мелкие части и снизить требования к памяти для каждого узла. Партиция - это основа параллелизма в Apache Spark.
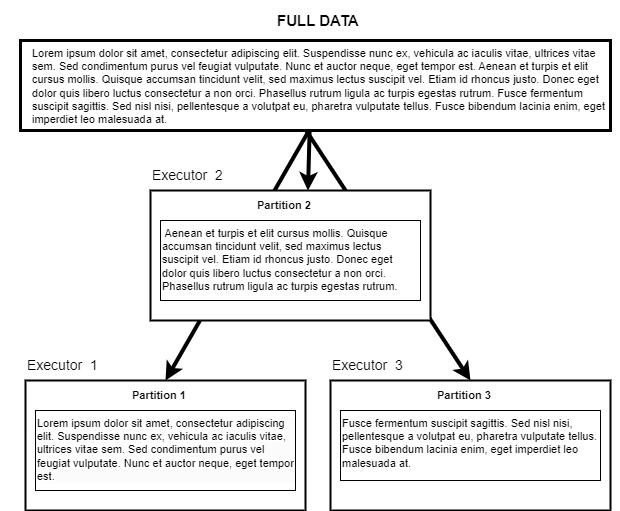
После того как пользователь отправил свое задание в кластер, каждая партиция передается определенному экзекьютору для дальнейшей обработки. Одновременно один экзекьютор обрабатывает только одну партицию, поэтому размер и количество партиций, передаваемых экзекьютору, прямо пропорциональны времени, которое требуется для их обработки.Вы можете манипулировать партициями, чтобы ускорить обработку данных.
Давайте посмотрим, как.
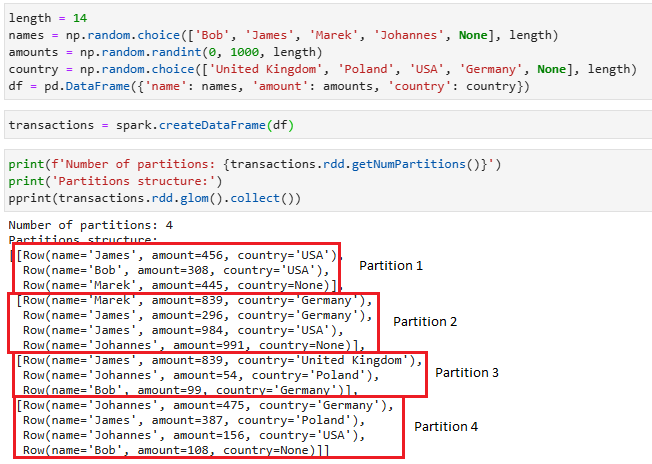
Взглянув на структуру партиций, мы видим, что наши данные разделены на четыре партиции (потому что у моего ноутбука 4 ядра), и если мы применим трансформации к этому датафрейму, то работа над кажой партицией будет выполняться в отдельном потоке (а в моем случае на каждом отдельном ядре процессора).
Зачем об этом думать?
Самая важная причина - производительность. Имея все данные, необходимые для вычислений, на одном узле, мы уменьшаем накладные расходы на перемешивание (необходимость сериализации и сетевой трафик).
Второй причиной является снижение затрат(в том числе денежной при использовании облачного кластера) - более эффективное использование кластера поможет сократить ресурсы на выполнение пользовательских заданий.
Repartition
Первый способ управления партициями - операция repartition(переразбиения).
Под переразбиением понимается операция по уменьшению или увеличению количества партиций, на которые будут разбиты данные. Этот процесс включает в себя полную перетасовку(shuffle). Repartition является дорогостоящим(в плане затрат на ресурсы) процессом. В типичном сценарии большая часть данных должна быть сериализована, перемещена и десериализована.
Пример:
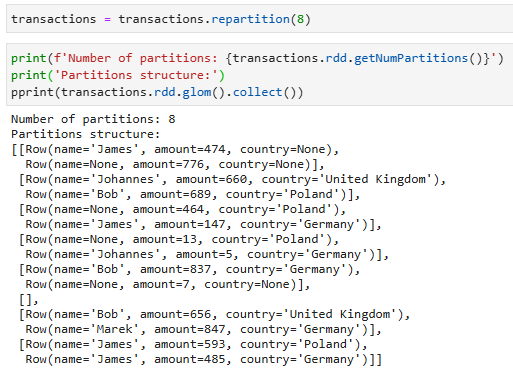
Мы видим, что количество партиций увеличилось до 8 и данные были перераспределены по партициям.
Помимо непосредственного указания количества партиций, вы можете передать имя столбца, по которому вы хотите разделить данные:

Мы видим, что количество партиций стало 200, и многие из этих партиций пусты. Этот момент мы обсудим чуть дальше.
Coalesce
Второй способ управления разделами - coalesce.
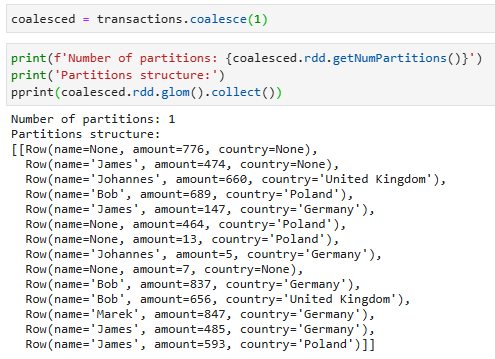
Эта операция уменьшает количество партиций и позволяет избежать перетасовки. Исполнитель может безопасно оставить данные на минимальном количестве партиций, перемещая их только с избыточных узлов. Поэтому при необходимости уменьшить количество разделов лучше использовать coalesce, а не repartition.
Однако следует понимать, что это может резко снизить параллельность обработки данных - coalesce часто продвигается дальше в цепочке трансформаций и может привести к тому, что для обработки будет задействовано меньше узлов, чем хотелось бы.
Пример:
Партиционирование на начальном этапе
Существует четкое соответствие между тем, как данные размещаются в хранилищах данных, таких как HDFS, и тем, как Spark разбивает данные на партиции при чтении.
Если у вас есть несжатый текстовый файл размером 1 ГБ, хранящийся в HDFS, то при стандартном размере блока HDFS (128 МБ) и стандартном spark.files.maxPartitionBytes(128 МБ) он будет храниться в 8 блоках.
Сколько партиций будет иметь DataFrame, который вы прочитаете из этого файла?
Давайте посмотрим в коде:
- Сгенерируем текстовый файл размером в 1 ГБ (1073741824 байт).

- Поместим его в HDFS и проверим размер блока

134217728 байт = 128 МБ - Проверим кол-во партиций
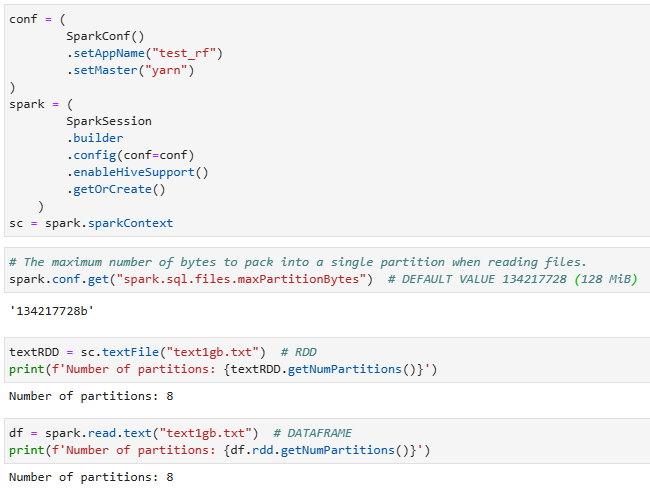
Начальное количество партиций в DataFrame вычисляется на основе параметра конфигурации spark.default.parallelism. Значение этого параметра дает нам количество ядер, имеющихся в нашем распоряжении. Мой тестовый кластер состоит из 3 машин. Каждый машина имеет 4 ядра. Из 3 машин 1 используется драйвером. Это означает, что в нашем распоряжении имеется 8 ядер (2 * 4).
Перемешивание партиций (без AQE)
Самое больное место любого приложения Spark - это широкие трансформации, которые требуют информации из других партиций и вызывают перетасовку(shuffle). К сожалению, избавиться от таких трансформаций все равно не удастся, но можно уменьшить влияние shuffle на производительность.
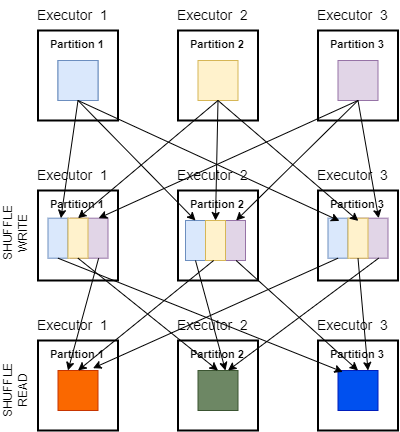
Shuffle partitions - это партиции, которые используются при перемешивании данных для широких партиций. Для широких трансформаций количество партиций после перемешивания становится равным 200. Неважно, мало у вас данные или много, или в конфигурации кластера 20 исполнителей или 100 - все равно будет 200 партиций. Да, это то, что мы видели в разделе repartition, это загадочное число.
Параметр, который управляет параллелизмом, возникающим в результате перемешивания, называется spark.sql.shuffle.partitions. Причина, по которой по умолчанию установлено значение 200, основана на реальном опыте, который показал, что это очень хорошее значение по умолчанию. Но на практике это значение обычно всегда плохое.
При работе с небольшими объемами данных обычно следует уменьшать количество партиций после перемешивания, иначе в итоге вы получите множество партиций с небольшим количеством записей в каждой партиции, что приведет к неполному использованию всех экзекьюторов и увеличит время передачи данных по сети от экзекьютора к экзекьютору.
Когда у вас слишком много данных и слишком мало партиций, это приводит к уменьшению количества задач в экзекьюторах, но увеличивает нагрузку на каждый отдельный экзекьютор и часто приводит к нехватке памяти(OutOfMemoryError). Кроме того, если вы увеличите размер партиции больше, чем доступная память в экзекьюторе, вы получите disk spill. Disk spill - это самая медленная вещь, которую вы, вероятно, сможете сделать. По сути, во время disk spill Spark помещает часть своей оперативной памяти на диск, что позволяет Sparkу хорошо работать с данными любого размера. Хотя это и не сломает ваш программу, но сделает ее супернеэффективной из-за дополнительных накладных расходов на дисковый ввод-вывод и увеличенной сборки мусора.
spark.sql.shuffle.partitions - один из наиболее часто настраиваемых параметров при работе со Spark.