Apache Spark написан на языке программирования Scala. Scala транслирует свой код в байт-код Java для выполнения на JVM(Java Virtual Machine).Поэтому необходимо понимать как устроена модель памяти Java(как JVM управляет памятью).
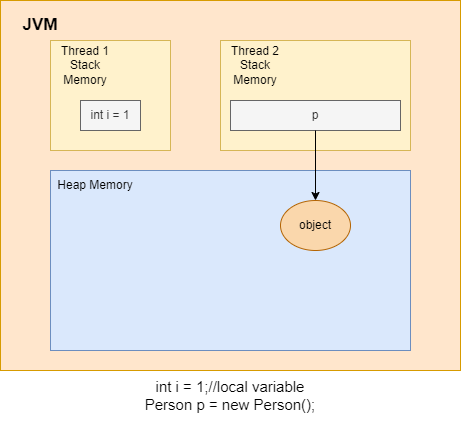
JVM делит память на область стека (stack) и область кучи (heap). Каждый раз, когда мы объявляем новые переменные, создаем объекты или вызываем новый метод, JVM выделяет память для этих операций в стеке или в куче.
Cтек
Стековая память в Java работает по схеме LIFO (Последний-зашел-Первый-вышел). Всякий раз, когда вызывается метод, в памяти стека создается новый блок, который содержит примитивы и ссылки на другие объекты в методе. Как только метод заканчивает работу, блок также перестает использоваться, тем самым предоставляя доступ для следующего метода.
Размер стековой памяти намного меньше объема памяти в куче.
Куча
Эта область памяти используется для динамического выделения памяти для объектов и классов JRE во время выполнения. Новые объекты всегда создаются в куче, а ссылки на них хранятся в стеке. Эти объекты имеют глобальный доступ и могут быть получены из любого места программы.
Разница между Stack и Heap памятью в Java:
- Куча используется всеми частями приложения в то время как стек используется только одним потоком исполнения программы.
- Всякий раз, когда создается объект, он всегда хранится в куче, а в памяти стека содержится ссылка на него. Память стека содержит только локальные переменные примитивных типов и ссылки на объекты в куче.
- Объекты в куче доступны с любой точки программы, в то время как стековая память не может быть доступна для других потоков.
- Управление памятью в стеке осуществляется по схеме LIFO.
- Стековая память является потокобезопасной, поскольку для каждого потока создается свой отдельный стек
- Стековая память существует лишь какое-то время работы программы, а память в куче живет с самого начала до конца работы программы.
- Мы можем использовать -Xms и -Xmx опции JVM, чтобы определить начальный и максимальный размер памяти в куче. Для стека определить размер памяти можно с помощью опции -Xss .
- Если память стека полностью занята, то Java Runtime бросает java.lang.StackOverflowError, а если память кучи заполнена, то бросается исключение java.lang.OutOfMemoryError: Java Heap Space.
- Размер памяти стека намного меньше памяти в куче. Из-за простоты распределения памяти (LIFO), стековая память работает намного быстрее кучи.
Уровни управления памятью
Существует несколько уровней управления памятью - уровень Spark, уровень Yarn, уровень JVM и уровень ОС. Мы будем перескакивать с одного уровня на другой и не будем обсуждать каждый из них подробно, но стоит понимать, какие уровни существуют, чтобы не запутаться.
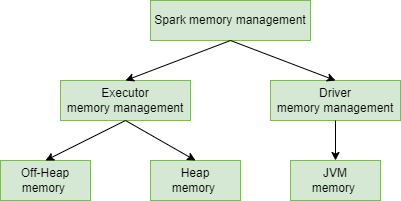
При запуске Spark-приложения кластер Spark запускает два процесса - Driver и Executor.
Драйвер - это главный процесс, отвечающий за создание контекста Spark, отправку заданий Spark и преобразование всего конвейера Spark в вычислительные единицы - задачи. Он также координирует планирование и оркестровку заданий на каждом экзекьюторе.
Управление памятью драйвера мало чем отличается от типичного процесса JVM и поэтому не будем его рассматривать. Экзекьютор отвечает за выполнение конкретных вычислительных задач на рабочих узлах и возврат результатов драйверу, а также обеспечивает хранение RDD. Посмотрим на управление его внутренней памятью.
Контейнер с экзекьютором
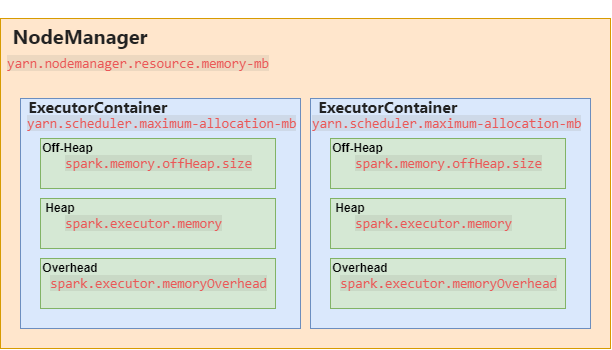
При отправке приложения Spark в кластер с помощью Yarn, ResourceManager обрабатывает запросы на память и выделяет контейнер экзекьютору до максимального размера, установленного параметром yarn.scheduler.maximum-allocation-mb. Запросы на память, превышающие указанное значение, не будут выполняться.
На отдельном узле это делает NodeManager. NodeManager имеет верхний предел доступных ему ресурсов, поскольку он ограничен ресурсами одного узла кластера. В Yarn он задается параметром yarn.nodemanager.resource.memory-mb. Это объем физической памяти на NodeManager, в МБ, который может быть выделен для контейнеров yarn.
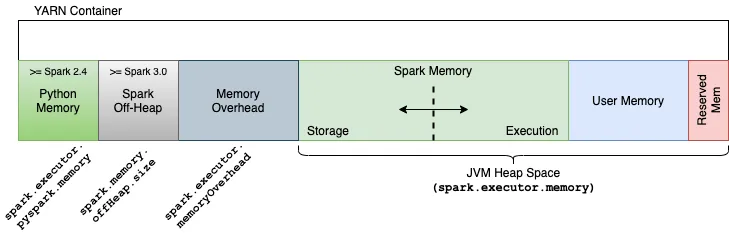
Один ExecutorContainer - это всего лишь одна JVM. Вся область памяти ExecutorContainer разделена на три секции:
Heap memory
Это объем памяти, указанный в параметре --executor-memory при отправке приложения Spark или при настройке spark.executor.memory. Это максимальная память кучи JVM (Xmx). Объекты здесь освобождаются сборщиком мусора (GC). Далее я буду называть эту часть памяти - память экзекьютора.
Off-heap memory
Spark позволяет использовать память вне кучи для определенных операций. При этом вы можете указать размер памяти вне кучи, которая будет использоваться вашим приложением.
Overhead memory
Это ремень безопасности для приложений Spark. Эта память используется для различных внутренних накладных расходов Spark.
Погружение в кучу
Как мы уже говорили, объем памяти, доступный каждому экзекьютору, контролируется параметром spark.executor.memory. Чтобы использовать и управлять этой частью памяти более эффективно, Spark логически и физически разделил эту часть памяти.
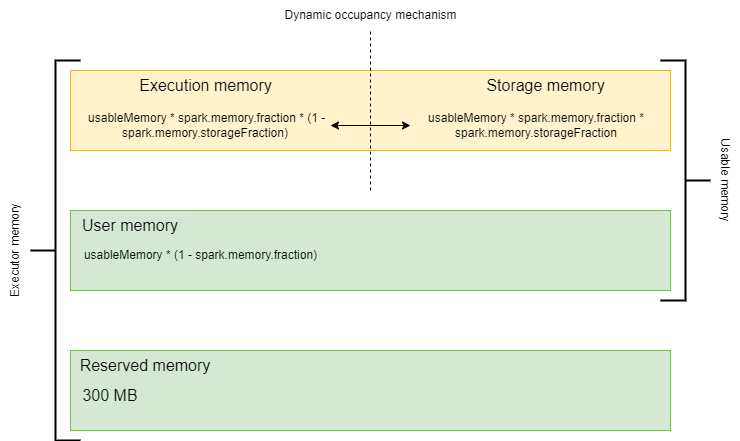
Зарезервированная память (Reserved Memory)
Spark резервирует эту память для своих собственных нужд. Зарезервированная память жестко закодирована и равна 300 МБ (значение RESERVED_SYSTEM_MEMORY_BYTES в исходном коде). В тестовом окружении (когда установлен spark.testing) мы можем изменить это значение с помощью spark.testing.reservedMemory.
Память хранилища (Storage Memory)
Память хранилища используется для кэширования и транслируемых(broadcasting) данных.
Размер памяти хранилища определяется следующим образом:
Storage Memory = usableMemory * spark.memory.fraction * spark.memory.storageFraction
По умолчанию память хранилища составляет 30% от всей используемой памяти (1 * 0,6 * 0,5 = 0,3).
Память выполнения (Execution Memory)
В основном она используется для хранения временных данных в операциях shuffle, join, sort, aggregation и т. д.
Скорее всего, если ваша программа работает слишком долго, проблема кроется в нехватке места здесь.
Размер памяти выполнения определяется следующим образом:
Execution Memory = usableMemory * spark.memory.fraction * (1 - spark.memory.storageFraction)
Как и память хранения, память выполнения также равна 30 % всей используемой памяти по умолчанию (1 * 0,6 * (1 - 0,5) = 0,3).
Пользовательская память (User Memory)
В основном используется для хранения данных, необходимых для трансформаций. В ней хранятся структуры данных, созданные и управляемые пользовательским кодом.
Размер пользовательской памяти определяется следующим образом:
User Memory = usableMemory * (1 - spark.memory.fraction)
По умолчанию это 1 * (1 - 0.6) = 0.4 - 40 % доступной памяти.
Механизм динамического заполнения(Dynamic occupancy mechanism)
Выполнение и хранение имеют общую память. Они могут одалживать ее друг у друга. Этот процесс называется механизмом динамического заполнения памяти.
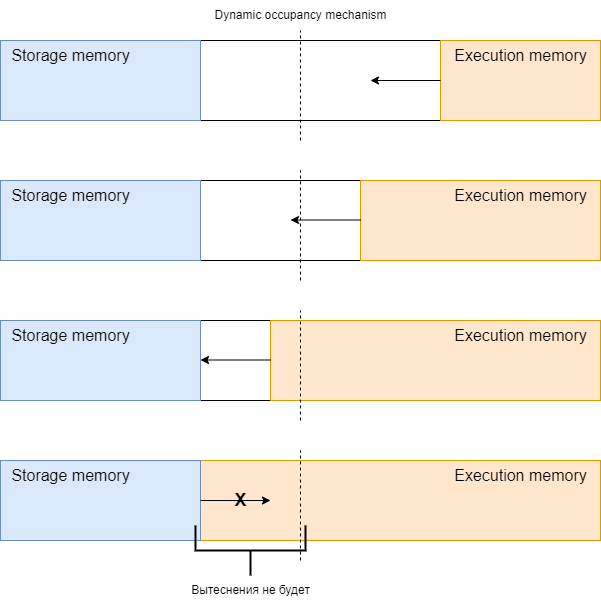
Когда память хранилища не использует весь доступный ей объем, память выполнения может занять столько памяти хранилища, сколько доступно. При возникновении потребности - память хранилища будет ждать, пока ее часть памяти не будет освобождена процессами экзекьютора.
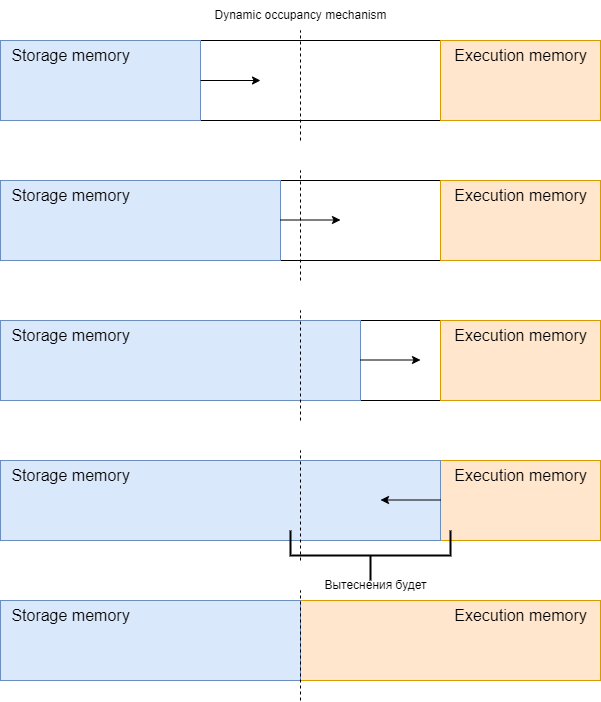
Когда память выполнения не используется, хранилище может занять столько памяти выполнения, сколько доступно, пока выполнение не затребует себе место. Когда это происходит, кэшированные блоки вытесняются из памяти до тех пор, пока не будет освобождено достаточно заимствованной памяти, чтобы удовлетворить запрос памяти исполнения.
Создатели этого механизма решили, что память выполнения имеет приоритет перед памятью хранения. У них были на то причины - выполнение задания важнее, чем кэшированные данные, а при возникновении OutOfMemoryError в процессе выполнения вся программа может потерпеть крах.
Память вне кучи(Off-heap memory)
Несмотря на то, что большинство операций происходит полностью в памяти кучи и с могучей помощью GC(сборщик мусора), Spark также позволяет использовать память вне кучи для определенных операций. Эта память не привязана к GC, поэтому в ней отсутствуют накладные расходы памяти: частое сканирование GC, сбор GC и повышается производительность работы с памятью.
Зная логику приложения, прямая работа с памятью может обеспечить значительный выигрыш в производительности, но также требует тщательного управления этим участком памяти. Это может быть нежелательно или даже невозможно в некоторых сценариях.
Если память вне кучи включена, у экзекьютора будет как память в куче, так и память вне кучи. Они дополняют друг друга - память выполнения будет суммой памяти выполнения в куче и памятью выполнения вне кучи. То же самое справедливо и для памяти хранилища.
В основном же, память вне кучи используется для Tungsten.
Tungsten это проект направленный на повышение производительности Spark-приложений за счет повышения эффективности работы процессора и памяти. Tungsten использует собственные сериализаторы/десериализаторы для представления объектов JVM в компактном формате, чтобы обеспечить высокую производительность и малый объем памяти.
По умолчанию память вне кучи отключена, но вы можете включить ее с помощью параметра spark.memory.offHeap.enabled и задать размер памяти с помощью параметра spark.memory.offHeap.size. Это не влияет на использование памяти кучи, но следите за тем, чтобы не превысить общий лимит памяти экзекьютора.
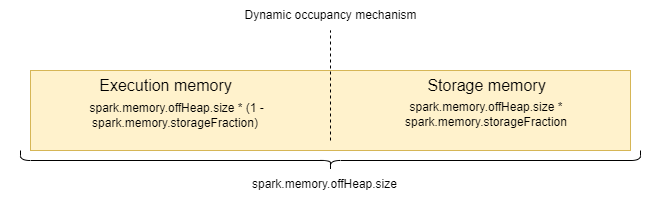
Модель памяти вне кучи относительно проста. Она включает только память хранилища и память выполнения. Эти две части могут заимствовать память друг у друга, по принципу описанному ранее(Механизм динамического заполнения).
Избыточная память(Overhead memory)
При выделении ExecutorContainer в кластерном режиме также выделяется дополнительная память для таких вещей, как накладные расходы VM. Эта память задается с помощью конфигурации spark.executor.memoryOverhead. По умолчанию размер составляет 10% от памяти исполнителя с минимальным размером 384 МБ.
Эта дополнительная память включает память для исполнителей PySpark, когда spark.executor.pyspark.memory не настроен.
В Spark 3.0 эта память не включает в себя память вне кучи.
Формула памяти
Общий объем памяти рассчитывается по следующей формуле:
totalMemMiB = (executorMemoryMiB + memoryOverheadMiB + memoryOffHeapMiB + pysparkMemToUseMiB)