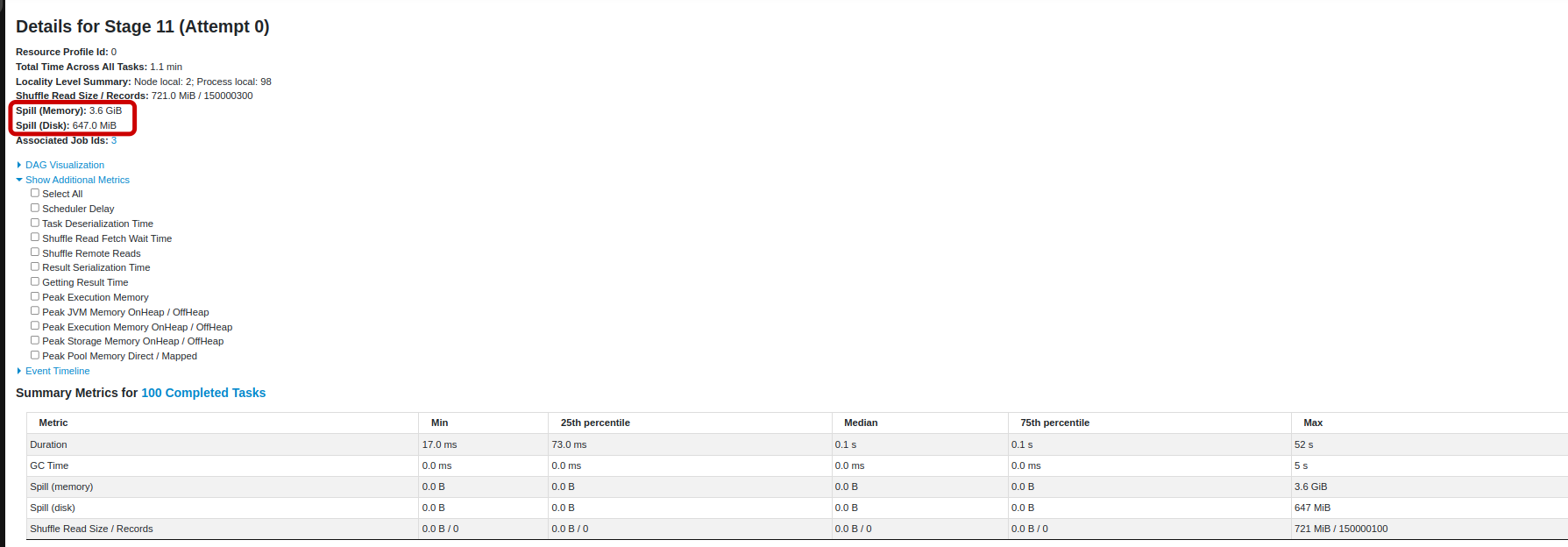
Spill (Memory)
Spill (Disk)
Spill это сброс данных на диск.
Раньше они назывались Shuffle spill (disk/memory) но были переименованы,
так как сброс данных может происходить и без перемешивания
commit
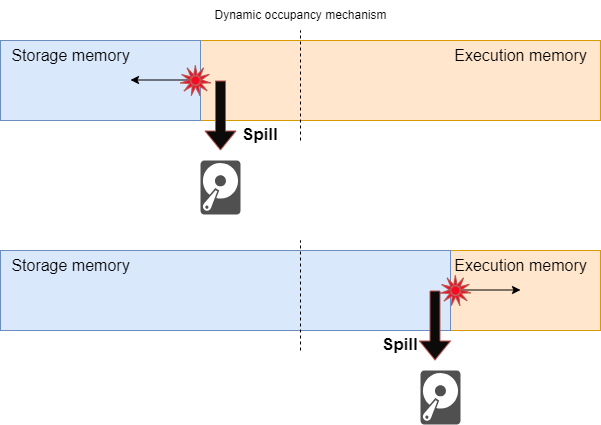
По своей сути, сброс данных означает ситуацию, в которой Apache Spark прибегает к записи промежуточных данных на диск,
когда ресурсов памяти недостаточно. Это происходит, когда размер набора данных или промежуточных результатов
превышает выделенный объем памяти, заставляя Spark сбрасывать данные на диск для хранения,
что по своей сути замедляет обработку, поскольку операции ввода-вывода на диске медленнее, чем операции в памяти.
 Пример приложения со спилом.
Пример приложения со спилом.
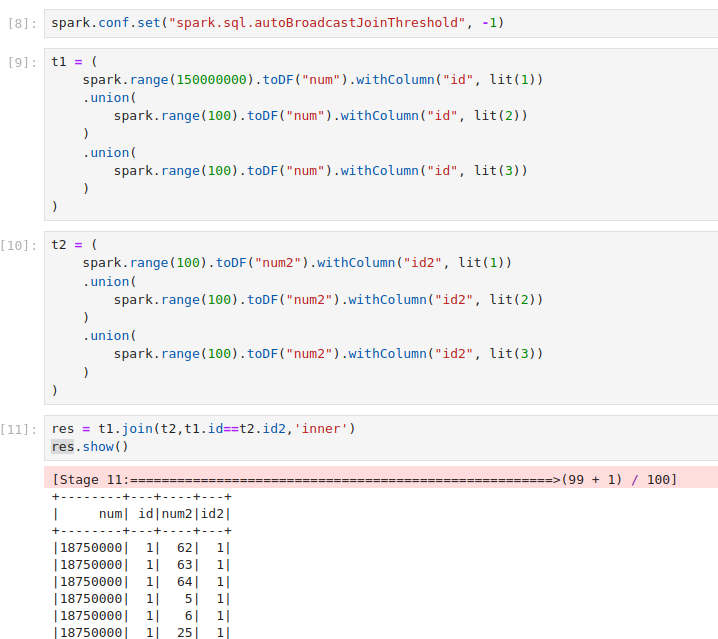
Данные в датафрейме t1 сильно «перекошены», т.е записей с id=1 очень много по сравнению с другими значениями id.
Если мы посмотрим на временную шкалу событий(Event Timeline), то сразу увидим причину спила.
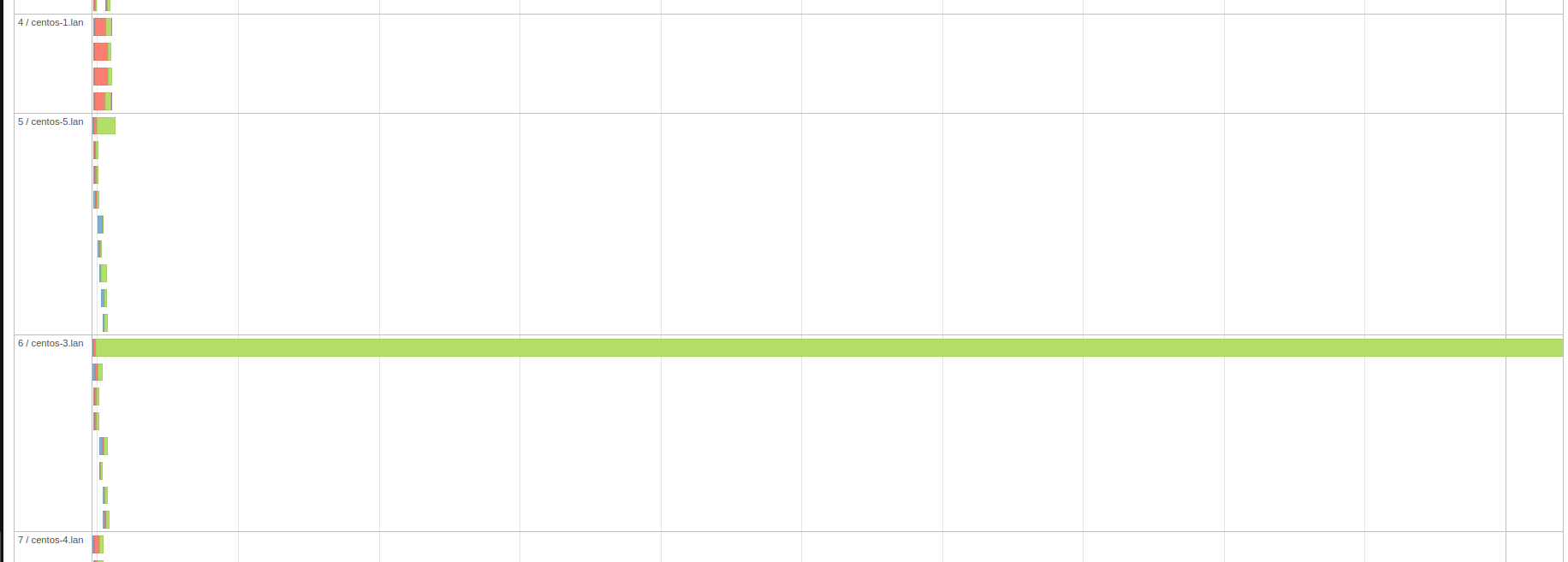
Из за перекоса данных один исполнитель обрабатывает все записи по ключу c id=1 и ему не хватает на это памяти.
Spill (Memory): 3.6 GiB это размер десериализованной формы данных в памяти.
Spill (Disk): 647.0 MiB это размер сериализованной формы данных на диске после того, как мы их записали.
Они описывают совершенно одну и ту же часть данных. Первая метрика описывает размер, занимаемый этими данными в памяти до того, как они были перемещены на диск, вторая описывает их размер при записи на диск. Эти две метрики могут отличаться, поскольку данные могут быть представлены по-разному при записи на диск, например, они могут быть сжаты.