Если вы хотите запустить приложение PySpark на YARN в кластерном режиме, вам необходимо убедиться,
что все используемые модули доступны на машинах кластера.
В противном случае вы можете получить ошибки, такие как .ModuleNotFoundError: No module named 'ИМЯМОДУЛЯ'
Вот скрипт myapptest.py который я хочу запустить в кластерном режиме:
from pyspark.conf import SparkConf
from pyspark.sql import SparkSession
from datetime import datetime, date
from pyspark.sql import Row
import pyspark
from transliterate import translit
import sys
print(f"PY VERSION IS {sys.version}")
print(f"PY EXEC IS {sys.executable}")
text = "Lorem ipsum dolor sit amet"
print(translit(text, 'ru'))
conf = (
SparkConf()
.set("spark.sql.adaptive.enabled", "true")
)
spark = (
SparkSession
.builder
.config(conf=conf)
.getOrCreate()
)
sc = spark.sparkContext
sc.setLogLevel("INFO")
df = spark.createDataFrame([
Row(a=1, b=2., c='string1', d=date(2000, 1, 1), e=datetime(2000, 1, 1, 12, 0)),
Row(a=2, b=3., c='string2', d=date(2000, 2, 1), e=datetime(2000, 1, 2, 12, 0)),
Row(a=4, b=5., c='string3', d=date(2000, 3, 1), e=datetime(2000, 1, 3, 12, 0))
])
df.show()
spark.stop()
На машинах кластера отсутствует модуль transliterate.
Я хочу создать виртуальное окружение(venv) с этой зависимостью и отправить его на кластер. В соответствии со статьей
делаю следуещее:
/opt/conda/envs/python_3.7/bin/python -m venv pvpvenv
source pvpvenv/bin/activate
pip install transliterate venv-pack
venv-pack -o pyspark_venv.tar.gz
Отправляю на кластер:
export HADOOP_CONF_DIR=/etc/hadoop/conf
export PYSPARK_PYTHON=./environment/bin/python
/opt/spark3/bin/spark-submit --master yarn --deploy-mode cluster \
--name cluster-test \
--conf spark.yarn.dist.archives=pyspark_venv.tar.gz#environment \
myapptest.py
И получаю ошибку:
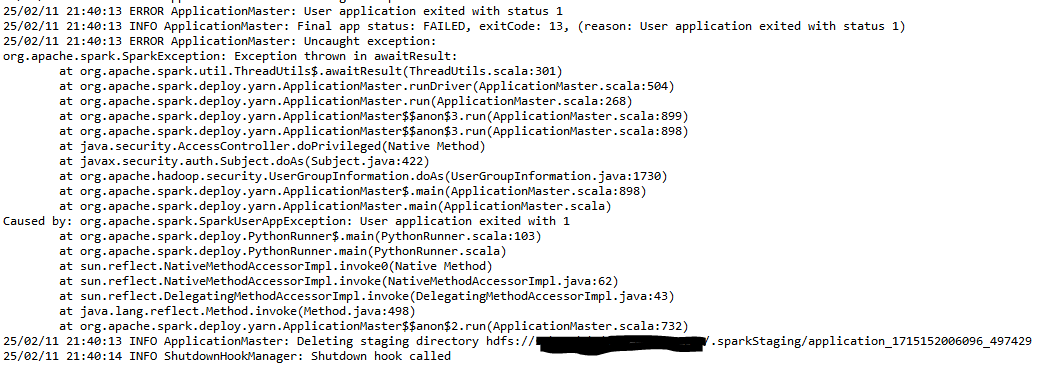
В логах YARN ошибка:

Разбор
Закомментил импорт transliterate, что бы посмотреть вывод
print(f"PY VERSION IS {sys.version}")
print(f"PY EXEC IS {sys.executable}")
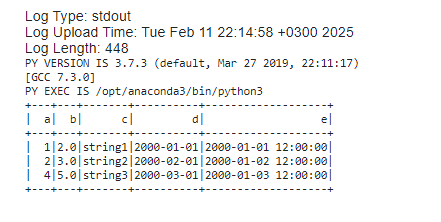
Как видим питон не тот, что передаем в PYSPARK_PYTHON
export PYSPARK_PYTHON=./environment/bin/python
Попробовал запустить, переда путь к питоны через conf
export HADOOP_CONF_DIR=/etc/hadoop/conf
/opt/spark3/bin/spark-submit --master yarn --deploy-mode cluster \
--name cluster-test \
--conf spark.yarn.dist.archives=pyspark_venv.tar.gz#environment \
--conf spark.pyspark.python=./environment/bin/python \
myapptest.py
Ошибка уже другая
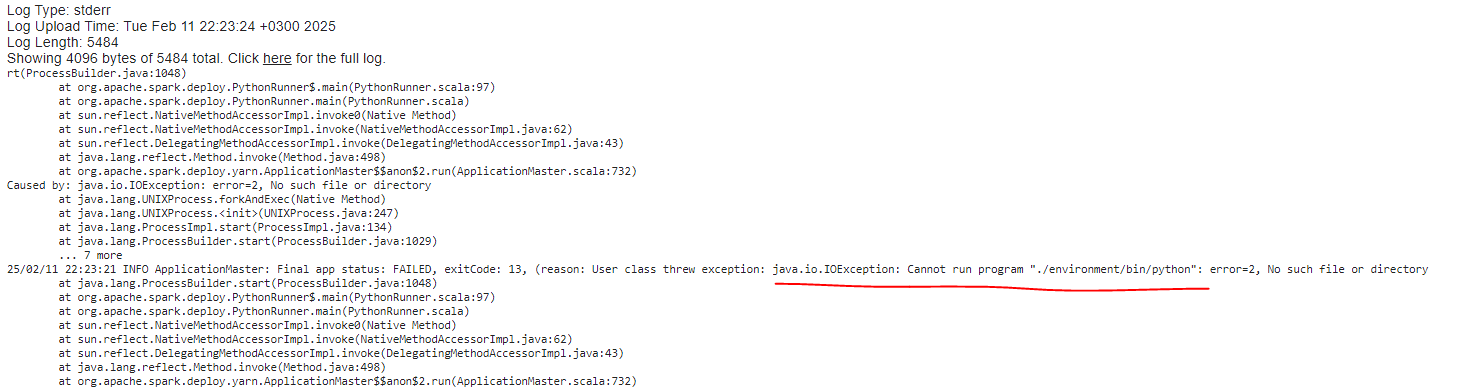
Детальнее изучив логи, замечаю проблему в симлинках
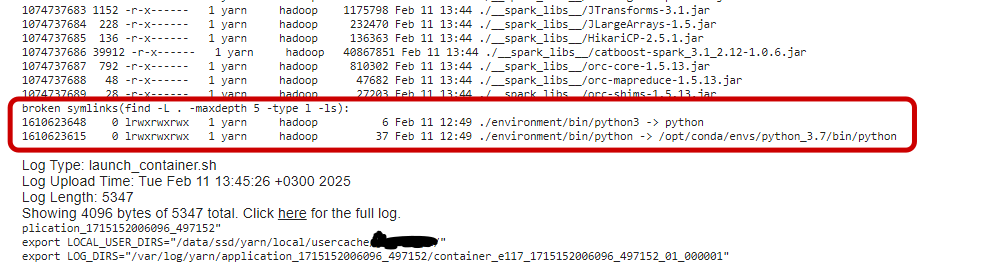
Распаковываю наш тар-файл и вижу, что симлинки указывают на интерпретатор питона, расположенный на машинке, где я упаковывал
виртуальное окружение. Конечно в кластере по такому пути питон отсутствует.
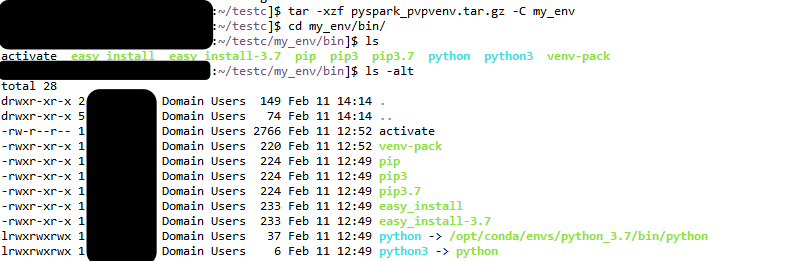
Решение
Так как venv-pack упаковывает интерпретатор Python как символическую ссылку, то нужно перепаковать наше виртуальное окружение,
указав правильную ссылку на питон в симлинке.
Покапавшись немного в параметрах venv-pack нахожу нужную нам опцию --python-prefix. Перепаковываем и запускаем.
venv-pack -o pyspark_venv.tar.gz --python-prefix /opt/anaconda3/
export HADOOP_CONF_DIR=/etc/hadoop/conf
/opt/spark3/bin/spark-submit --master yarn --deploy-mode cluster \
--name cluster-test \
--conf spark.yarn.dist.archives=pyspark_venv.tar.gz#environment \
--conf spark.pyspark.python=./environment/bin/python \
myapptest.py

Успех)
Учтите что venv-pack довольно древний и не лишен багов.
Важный баг с симлинками